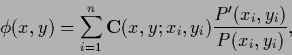To solve the nonlinear Eq. (609)
by iteration
one has to begin with an initial configuration ![]() .
In principle any easy to use technique for density estimation
could be chosen to construct starting guesses
.
In principle any easy to use technique for density estimation
could be chosen to construct starting guesses ![]() .
.
One possibility to obtain initial guesses
is to neglect some terms of the full stationarity equation
and solve the resulting simpler (ideally linear)
equation first.
The corresponding solution may be taken as initial guess
![]() for solving the full equation.
for solving the full equation.
Typical error functionals
for statistical learning problems
include a term ![]() consisting
of a discrete sum over a finite number
consisting
of a discrete sum over a finite number ![]() of training data.
For diagonal
of training data.
For diagonal
![]() those contributions
result (355) in
those contributions
result (355) in
![]()
![]() -peak contributions to the inhomogeneities
-peak contributions to the inhomogeneities ![]() of the stationarity equations,
like
of the stationarity equations,
like
![]() in Eq. (143)
or
in Eq. (143)
or
![]() in Eq. (172).
To find an initial guess, one can
now keep only that
in Eq. (172).
To find an initial guess, one can
now keep only that ![]() -peak contributions
-peak contributions ![]() arising from the training data
and ignore the other, typically continuous parts of
arising from the training data
and ignore the other, typically continuous parts of ![]() .
For (143) and (172)
this means setting
.
For (143) and (172)
this means setting ![]() and yields a truncated equation
and yields a truncated equation
| (680) |
In general, a
![]() can be chosen.
This is necessary if
can be chosen.
This is necessary if ![]() is not invertible
and can also be useful if its inverse is difficult to calculate.
One possible choice for the kernel is the inverse negative Hessian
is not invertible
and can also be useful if its inverse is difficult to calculate.
One possible choice for the kernel is the inverse negative Hessian
![]() evaluated
at some initial configuration
evaluated
at some initial configuration ![]() or an approximation of it.
A simple possibility to construct an invertible operator from a
noninvertible
or an approximation of it.
A simple possibility to construct an invertible operator from a
noninvertible ![]() would be
to add a mass term
would be
to add a mass term
| (682) |
Solving a truncated equation of the form (681)
with ![]() means skipping the term
means skipping the term
![]() from the exact relation
from the exact relation
A similar possibility is to start with
an ``empirical solution''
| (684) |
| (685) |
Similarly to Eq. (681),
it is often also useful to choose a (for example smoothing) kernel ![]() and use as initial guess
and use as initial guess
We will now discuss the cases ![]() and
and ![]() in some more detail.
in some more detail.