



Next: Normalization by parameterization: Error
Up: Gaussian prior factor for
Previous: Gaussian prior factor for
Contents
Lagrange multipliers: Error functional 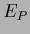
We write
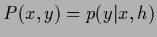 for
the probability of
for
the probability of 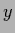 conditioned on
conditioned on 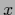 and
and 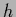 .
We consider now a regularizing term which is quadratic in
.
We consider now a regularizing term which is quadratic in 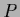 instead of
instead of 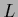 .
This corresponds to a factor
within the posterior probability (the specific prior)
which is Gaussian with respect to .
.
This corresponds to a factor
within the posterior probability (the specific prior)
which is Gaussian with respect to .
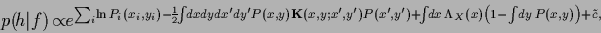 |
(162) |
or written in terms of 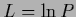 for comparison,
for comparison,
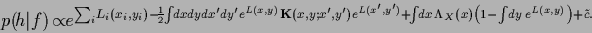 |
(163) |
Hence, the error functional is
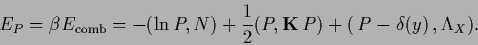 |
(164) |
In particular, the choice 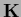 =
=
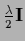 , i.e.,
, i.e.,
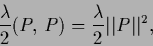 |
(165) |
can be interpreted as a smoothness prior with respect to the
distribution function of (see Section 3.3).
In functional (164) we have only implemented
the normalization condition for by a Lagrange multiplier
and not the non-negativity constraint.
This is sufficient if 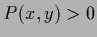 (i.e.,
(i.e.,  not equal zero)
at the stationary point because then
holds also in some neighborhood
and there are no components of the gradient pointing
into regions with negative probabilities.
In that case the non-negativity
constraint is not active at the stationarity point.
As probabilities have to be positive at data points,
smoothness constraints
result for example typically
in positive probabilities everywhere
where not set to zero explicitly by boundary conditions.
If, however, the stationary point has locations
with =
not equal zero)
at the stationary point because then
holds also in some neighborhood
and there are no components of the gradient pointing
into regions with negative probabilities.
In that case the non-negativity
constraint is not active at the stationarity point.
As probabilities have to be positive at data points,
smoothness constraints
result for example typically
in positive probabilities everywhere
where not set to zero explicitly by boundary conditions.
If, however, the stationary point has locations
with = 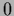 at non-boundary points, then
the component of the gradient
pointing in the region with negative probabilities
has to be projected out by introducing
Lagrange parameters for each .
This may happen, for example, if the regularizer
rewards oscillatory behavior.
at non-boundary points, then
the component of the gradient
pointing in the region with negative probabilities
has to be projected out by introducing
Lagrange parameters for each .
This may happen, for example, if the regularizer
rewards oscillatory behavior.
The stationarity equation for is
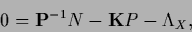 |
(166) |
with the diagonal matrix
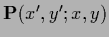 =
=
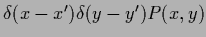 ,
or multiplied by
,
or multiplied by 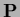
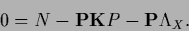 |
(167) |
Probabilities
are unequal zero at observed data points 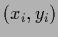 so
so
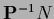 is well defined.
is well defined.
Combining the normalization condition Eq. (135)
for
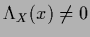 with Eq. (166) or (167)
the Lagrange multiplier function
with Eq. (166) or (167)
the Lagrange multiplier function 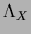 is found as
is found as
 |
(168) |
where
Eliminating in Eq. (166)
by using Eq. (168)
gives finally
 |
(169) |
or for Eq. (167)
 |
(170) |
For similar reasons as has been discussed
for Eq. (141)
unnormalized solutions fulfilling
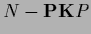 are possible.
Defining
are possible.
Defining
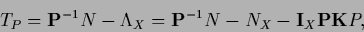 |
(171) |
the stationarity equation can be written
analogously to Eq. (143) as
 |
(172) |
with 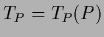 ,
suggesting for existing
,
suggesting for existing
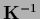 an iteration
an iteration
 |
(173) |
starting from some initial guess 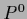 .
.
Next: Normalization by parameterization: Error
Up: Gaussian prior factor for
Previous: Gaussian prior factor for
Contents
Joerg_Lemm
2001-01-21