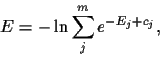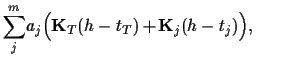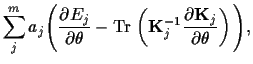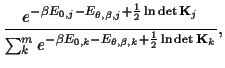In general density estimation
the predictive density can only be calculated
approximately, e.g.
in maximum a posteriori approximation
or by Monte Carlo methods.
For Gaussian regression, however the predictive density
of mixture models can be calculated exactly
for given ![]() (and
(and ![]() ).
This provides us with the
opportunity to compare the simultaneous
maximum posterior approximation
with respect to
).
This provides us with the
opportunity to compare the simultaneous
maximum posterior approximation
with respect to ![]() and
and ![]() with an analytical
with an analytical ![]() -integration
followed by a
maximum posterior approximation
with respect to
-integration
followed by a
maximum posterior approximation
with respect to ![]() .
.
Maximising the posterior
(with respect to ![]() ,
, ![]() , and
possibly
, and
possibly ![]() )
is equivalent to minimising
the mixture energy
(regularised error functional
[13,17,15,16])
)
is equivalent to minimising
the mixture energy
(regularised error functional
[13,17,15,16])
| (20) |
In a direct saddle point approximation with respect
to ![]() and
and ![]() stationarity equations
are obtained by setting the (functional)
derivatives with respect
to
stationarity equations
are obtained by setting the (functional)
derivatives with respect
to ![]() and
and ![]() to zero,
to zero,
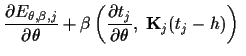 |
|||
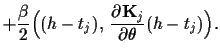 |
(24) |
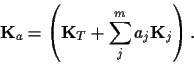 |
(26) |