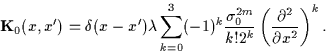[@twocolumnfalse
J. C. Lemm
February 2, 2000
Institut für Theoretische Physik I, Universität Münster, 48149 Münster, Germany
03.65.-w, 02.50.Rj, 02.50.Wp ]
The first step to be done when applying quantum mechanics to a real world system is the reconstruction of its Hamiltonian from observational data. Such a reconstruction, also known as inverse problem, constitutes a typical example of empirical learning. Whereas the determination of potentials from spectral and from scattering data has been studied in much detail in inverse spectral and inverse scattering theory [1,2], this Paper describes the reconstruction of potentials by measuring particle positions in coordinate space for finite quantum systems in time-dependent states. The presented method can easily be generalized to other forms of observational data.
In the last years much effort has been devoted to many other practical empirical learning problems, including, just to name a few, prediction of financial time series, medical diagnosis, and image or speech recognition. This also lead to a variety of new learning algorithms, which should in principle also be applicable to inverse quantum problems. In particular, this Paper shows how the Bayesian framework [3] can be applied to solve problems of inverse time-dependent quantum mechanics (ITDQ). The presented method generalizes a recently introduced approach for stationary quantum systems [4,5]. Compared to stationary inverse problems, the observational data in time-dependent problems are more indirectly related to potentials, making them in general more difficult to solve.
Specifically, we will study
the following type of observational data:
Preparing a particle
in an eigenstate of the position operator with coordinates ![]() at time
at time ![]() , we let
this state evolve in time
according to the rules of quantum mechanics
and measure its new position at time
, we let
this state evolve in time
according to the rules of quantum mechanics
and measure its new position at time ![]() ,
finding a value
,
finding a value ![]() .
Continuing from this measured position
.
Continuing from this measured position ![]() ,
we measure the particle position again at time
,
we measure the particle position again at time ![]() ,
and repeat this procedure
until
,
and repeat this procedure
until ![]() data points
data points ![]() at times
at times ![]() have been collected.
We thus end up with observational data of the form
have been collected.
We thus end up with observational data of the form
![]() =
=
![]() ,
where
,
where ![]() is the result of the
is the result of the ![]() -th coordinate measurement,
-th coordinate measurement,
![]() =
= ![]() the time interval
between two subsequent measurements
and
the time interval
between two subsequent measurements
and ![]() the coordinates
of the previous observation (or preparation) at time
the coordinates
of the previous observation (or preparation) at time ![]() .
.
We will discuss in particular systems with
time-independent Hamiltonians of the form
![]() =
= ![]() ,
consisting of a standard kinetic energy term
,
consisting of a standard kinetic energy term ![]() and a local potential
and a local potential
![]() =
=
![]() ,
with
,
with ![]() denoting the position of the particle.
In that case, the aim is the reconstruction of the function
denoting the position of the particle.
In that case, the aim is the reconstruction of the function ![]() from observational data
from observational data ![]() .
(The restriction to local potentials simplifies the numerical calculations.
Nonlocal Hamiltonians can be reconstructed similarly.)
.
(The restriction to local potentials simplifies the numerical calculations.
Nonlocal Hamiltonians can be reconstructed similarly.)
Setting up a Bayesian model
requires the definition of two probabilities:
1. the probability ![]() to measure data
to measure data ![]() given potential
given potential ![]() ,
which,
for
,
which,
for ![]() considered fixed,
is also known as the likelihood of
considered fixed,
is also known as the likelihood of ![]() ,
and 2. a prior probability
,
and 2. a prior probability ![]() implementing available a priori information
concerning the potential to be reconstructed.
implementing available a priori information
concerning the potential to be reconstructed.
Referring to a maximum a posteriori approximation (MAP)
we understand those potentials ![]() to be solutions of the
reconstruction problem,
which maximize
to be solutions of the
reconstruction problem,
which maximize ![]() , i.e., the
posterior probability of
, i.e., the
posterior probability of ![]() given all available data
given all available data ![]() .
The basic relation is then Bayes' theorem,
according to which
.
The basic relation is then Bayes' theorem,
according to which
![]() .
.
One possibility is to choose a parametric ansatz for the potential ![]() .
In that case, an additional prior term
.
In that case, an additional prior term ![]() is often not included
(so the MAP becomes a maximum likelihood approximation).
In the following,
we concentrate on nonparametric approaches,
which are less restrictive
compared to their parametric counterparts.
Their large flexibility, however,
makes it essential to include (nonuniform) priors.
Corresponding nonparametric priors
are formulated explicitly in terms of the function
is often not included
(so the MAP becomes a maximum likelihood approximation).
In the following,
we concentrate on nonparametric approaches,
which are less restrictive
compared to their parametric counterparts.
Their large flexibility, however,
makes it essential to include (nonuniform) priors.
Corresponding nonparametric priors
are formulated explicitly in terms of the function ![]() [6].
Indeed, nonparametric priors are well known from
applications to
regression [7],
classification [8],
general density estimation [9],
and stationary inverse quantum problems [4,5].
It is the likelihood model, discussed next, which is specific for ITDQ.
[6].
Indeed, nonparametric priors are well known from
applications to
regression [7],
classification [8],
general density estimation [9],
and stationary inverse quantum problems [4,5].
It is the likelihood model, discussed next, which is specific for ITDQ.
According to the axioms of quantum mechanics
the probability that a particle is found at
position ![]() at time
at time ![]() ,
provided the particle has been at
,
provided the particle has been at ![]() at time
at time ![]() ,
is given by
,
is given by
| (3) |
Having defined the likelihood model of ITDQ,
in the next step a prior for ![]() has to be chosen.
A convenient
nonparametric prior
has to be chosen.
A convenient
nonparametric prior ![]() is a Gaussian
is a Gaussian
If available, it is useful to include
some information about the ground state energy ![]() ,
which helps to determine the depth of the potential.
This can, for example,
be a noisy measurement of the ground state energy
which, assuming Gaussian noise,
is implemented by
,
which helps to determine the depth of the potential.
This can, for example,
be a noisy measurement of the ground state energy
which, assuming Gaussian noise,
is implemented by
Combining
(5)
and
(6)
with (1) for
![]() repeated coordinate measurements
starting from an initial position
repeated coordinate measurements
starting from an initial position ![]() ,
we obtain for the posterior (7),
,
we obtain for the posterior (7),
| (12) |
As the next step,
we want to check the numerical feasibility of a nonparametric reconstruction
of the potential ![]() for a one-dimensional quantum system.
For that purpose, we choose
a system with the true potential
for a one-dimensional quantum system.
For that purpose, we choose
a system with the true potential
Besides a noisy energy measurement of the form (6)
we include a Gaussian prior (5)
with a smoothness related inverse covariance
| (19) | |||
Fig. 4
compares the sum over empirical transition probabilities
![]() as
derived from the observational data
as
derived from the observational data ![]() with the corresponding true
with the corresponding true
![]() =
=
![]() and reconstructed
and reconstructed
![]() =
=
![]() .
Due to the summation over data points with different
.
Due to the summation over data points with different ![]() ,
the quantities shown in Fig. 4
do not present the complete information which is available to the algorithm.
Hence, Fig. 5 depicts the corresponding quantities
for a fixed
,
the quantities shown in Fig. 4
do not present the complete information which is available to the algorithm.
Hence, Fig. 5 depicts the corresponding quantities
for a fixed ![]() .
In particular, Fig. 5 compares
the reconstructed transition probability (1)
with the corresponding empirical and true transition probabilities
for a particle having been at time
.
In particular, Fig. 5 compares
the reconstructed transition probability (1)
with the corresponding empirical and true transition probabilities
for a particle having been at time ![]() at position
at position ![]() =1.
The ITDQ algorithm returns an
approximation for all such transition probabilities.
=1.
The ITDQ algorithm returns an
approximation for all such transition probabilities.
Figs. 4 and 5 show,
that the reconstructed ![]() tends to produce a better approximation of the
empirical probabilities
than the true potential
tends to produce a better approximation of the
empirical probabilities
than the true potential ![]() .
Indeed,
the error on the data or negative log-likelihood,
.
Indeed,
the error on the data or negative log-likelihood,
![]() =
=
![]() ,
being a canonical error measure in density estimation,
is smaller for
,
being a canonical error measure in density estimation,
is smaller for ![]() than for
than for ![]() .
A smaller
.
A smaller ![]() ,
i.e., a lower influence of the prior,
produces a still smaller error
,
i.e., a lower influence of the prior,
produces a still smaller error
![]() .
At the same time, however,
the reconstructed potential becomes more wiggly for smaller
.
At the same time, however,
the reconstructed potential becomes more wiggly for smaller ![]() ,
being the symptom of the well known effect of ``overfitting''.
The (true) generalization error
,
being the symptom of the well known effect of ``overfitting''.
The (true) generalization error
![]() =
=
![]() [with uniform
[with uniform ![]() ], on the other hand,
can never be smaller for the reconstructed
], on the other hand,
can never be smaller for the reconstructed ![]() than for
than for ![]() .
As it is typical for most empirical learning problems,
the generalization error
.
As it is typical for most empirical learning problems,
the generalization error
![]() shows a minimum as function of
shows a minimum as function of ![]() .
It is this minimum which gives the optimal value for
.
It is this minimum which gives the optimal value for ![]() .
Knowledge of the true model
allows in our case to calculate the generalization error exactly.
If, as usual, the true model is not known,
classical cross-validation [6]
and bootstrap [11] techniques
can be used
to approximate the generalization error as function of
.
Knowledge of the true model
allows in our case to calculate the generalization error exactly.
If, as usual, the true model is not known,
classical cross-validation [6]
and bootstrap [11] techniques
can be used
to approximate the generalization error as function of ![]() empirically.
empirically.
Alternatively to optimizing ![]() or other hyperparameters
one can integrate over them [10].
Similarly, studying the feasibility
of a Bayesian Monte Carlo approach,
contrasting the MAP approach of this paper,
would certainly be interesting.
or other hyperparameters
one can integrate over them [10].
Similarly, studying the feasibility
of a Bayesian Monte Carlo approach,
contrasting the MAP approach of this paper,
would certainly be interesting.
In summary, this Paper has presented a new method to solve inverse problems for time-dependent quantum systems. The approach, based on a Bayesian framework, is able to handle quite general types of observational data. Numerical calculations proved to be feasible for a one dimensional model.
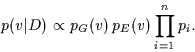
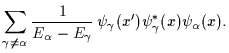
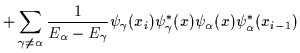
![$\displaystyle +
\sum_{\gamma\ne \alpha} \frac{1}{E_\alpha-E_\gamma}
\psi_\gamma^*(x_{i-1})\psi_\gamma(x) \psi_\alpha^* (x)
\psi_\alpha(x_i)
\Big]
.$](img101.gif)