



Next: Prior mixtures
Up: Mixtures of Gaussian process
Previous: The Bayesian model
Contents
Gaussian regression
In general density estimation problems
 is not restricted to a special form,
provided it is non-negative and normalised
[9,10].
In this paper we concentrate on Gaussian regression
where the single data likelihoods are assumed to be Gaussians
is not restricted to a special form,
provided it is non-negative and normalised
[9,10].
In this paper we concentrate on Gaussian regression
where the single data likelihoods are assumed to be Gaussians
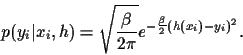 |
(6) |
In that case the
unknown regression function  represents the hidden variables
and
represents the hidden variables
and  -integration means
functional integration
-integration means
functional integration
 .
.
As simple building blocks for mixture priors
we choose Gaussian (process) prior components
[2,17,14],
| |
|
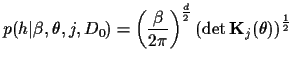 |
|
| |
|
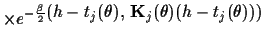 |
(7) |
the scalar product notation
 standing for
standing for  -integration.
The mean
-integration.
The mean
 will in the following
also be called an (adaptive) template function.
Covariances
will in the following
also be called an (adaptive) template function.
Covariances
 are real, symmetric, positive (semi-)definite
(for positive semidefinite covariances the null space has to be projected out).
The dimension
are real, symmetric, positive (semi-)definite
(for positive semidefinite covariances the null space has to be projected out).
The dimension  of the -integral
becomes infinite for an infinite number of -values
(e.g. continuous ).
The infinite factors appearing thus
in numerator and denominator of (5)
however cancel.
Common smoothness priors
have
of the -integral
becomes infinite for an infinite number of -values
(e.g. continuous ).
The infinite factors appearing thus
in numerator and denominator of (5)
however cancel.
Common smoothness priors
have
 and as
and as  a differential operator,
e.g., the negative Laplacian.
a differential operator,
e.g., the negative Laplacian.
Analogously to simulated annealing
it will appear to be very useful to vary
the `inverse temperature'  simultaneously
in (6) (for training but not necessarily for test data)
and (7).
Treating not as a fixed variable,
but including it explicitly as hidden variable,
the formulae of Sect. 2 remain valid,
provided the replacement
simultaneously
in (6) (for training but not necessarily for test data)
and (7).
Treating not as a fixed variable,
but including it explicitly as hidden variable,
the formulae of Sect. 2 remain valid,
provided the replacement
 is made, e.g.
is made, e.g.
 (see also Fig.1).
(see also Fig.1).
Typically, inverse prior covariances can be related to
approximate symmetries.
For example, assume we expect the regression function to be
approximately invariant under a permutation of its arguments
 with
with
 denoting a permutation.
Defining an operator
denoting a permutation.
Defining an operator  acting on according to
acting on according to
 ,
we can define a prior process with
inverse covariance
,
we can define a prior process with
inverse covariance
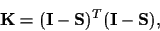 |
(8) |
with identity  and the superscript
and the superscript  denoting the transpose
of an operator.
The corresponding prior energy
denoting the transpose
of an operator.
The corresponding prior energy
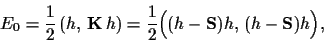 |
(9) |
is a measure of the deviation of from
an exact symmetry under .
Similarly,
we can consider a Lie group
=
 with
with  being the generator
of the infinitesimal symmetry transformation.
In that case
a covariance
being the generator
of the infinitesimal symmetry transformation.
In that case
a covariance
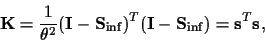 |
(10) |
with prior energy
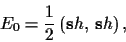 |
(11) |
can be used to implement approximate invariance
under the infinitesimal symmetry transformation
 =
=
 .
For appropriate boundary conditions,
a negative Laplacian
.
For appropriate boundary conditions,
a negative Laplacian  can thus be interpreted as
enforcing approximate invariance under
infinitesimal translations, i.e., for
=
can thus be interpreted as
enforcing approximate invariance under
infinitesimal translations, i.e., for
=
 .
.
Next: Prior mixtures
Up: Mixtures of Gaussian process
Previous: The Bayesian model
Contents
Joerg_Lemm
1999-12-21