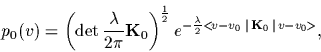In this section we include, in addition to the likelihood terms,
a priori information in form of a prior density ![]() .
Having specified
.
Having specified ![]() a Bayesian approach aims at
calculating the predictive density (3).
Within a maximum posterior approximation
the functional integral in Eq. (3)
can be calculated by Monte Carlo methods
or, as we will do in the following,
in saddle point approximation, i.e., by selecting
the potential with maximal posterior.
The posterior density of
a Bayesian approach aims at
calculating the predictive density (3).
Within a maximum posterior approximation
the functional integral in Eq. (3)
can be calculated by Monte Carlo methods
or, as we will do in the following,
in saddle point approximation, i.e., by selecting
the potential with maximal posterior.
The posterior density of ![]() is
according to Eq. (1) proportional to the product
of training likelihood and prior
is
according to Eq. (1) proportional to the product
of training likelihood and prior
Technically the most convenient priors are
Gaussian processes
which we already have introduced in
(8) for regression models.
Such priors read for ![]() ,
,
Finally, we want to mention that
also the prior density can be parameterized,
making it more flexible.
Parameters of the prior density, also known as hyperparameters,
are in a Bayesian framework
included as integration variables in Eq. (3),
or, in maximum posterior approximation,
in the maximization of Eq. (5)
[22,26].
Hyperparameters allow to transform
the point-like maxima of Gaussian priors
to submanifolds of optimal solutions.
For a Gaussian process prior, for example,
the mean or reference potential ![]() and the covariance
and the covariance
![]() can so be adapted to the data
[32].
can so be adapted to the data
[32].