A.1: n-gram Statistik bestimmen
Contents
A.1: n-gram Statistik bestimmen#
Statistische Modelle werden oft zur Texterkennung und -generierung verwendet. Sie erheben die Wahrscheinlichkeiten von Wortfolgen. Eine häufige Methode dafür sind sogenannte n-gram-Modelle. Diese Modelle basieren auf der Wahrscheinlichkeit von Wortfolgen in einem Textkorpus.
Ein n-gram-Modell betrachtet eine Sequenz von \(n\) Wörtern in einem Text und verwendet diese, um die Wahrscheinlichkeit des nächsten Wortes in der Sequenz vorherzusagen. Zum Beispiel würde ein 2-gram-Modell (auch als bigram-Modell bezeichnet) für eine Sequenz von zwei aufeinanderfolgenden Wörtern die Wahrscheinlichkeit/Häufigkeit betrachten, mit der diese in einem Textkorpus vorkommen.
Um ein n-gram-Modell zu trainieren, wird ein Korpus von Texten verwendet, um die Wahrscheinlichkeiten der Wortfolgen abzuschätzen. Dies geschieht durch Zählen der Anzahl der Vorkommen von n-grammen im Korpus und der Berechnung ihrer Häufigkeit. Die Häufigkeiten können dann verwendet werden, um die Wahrscheinlichkeit von bestimmten Wortfolgen im Korpus zu berechnen.
Diese Wahrscheinlichkeiten können dann verwendet werden, um neue Texte zu generieren, indem man eine Sequenz von Wörtern beginnt und dann das nächste Wort basierend auf den Wahrscheinlichkeiten der Wortfolgen im Korpus auswählt.
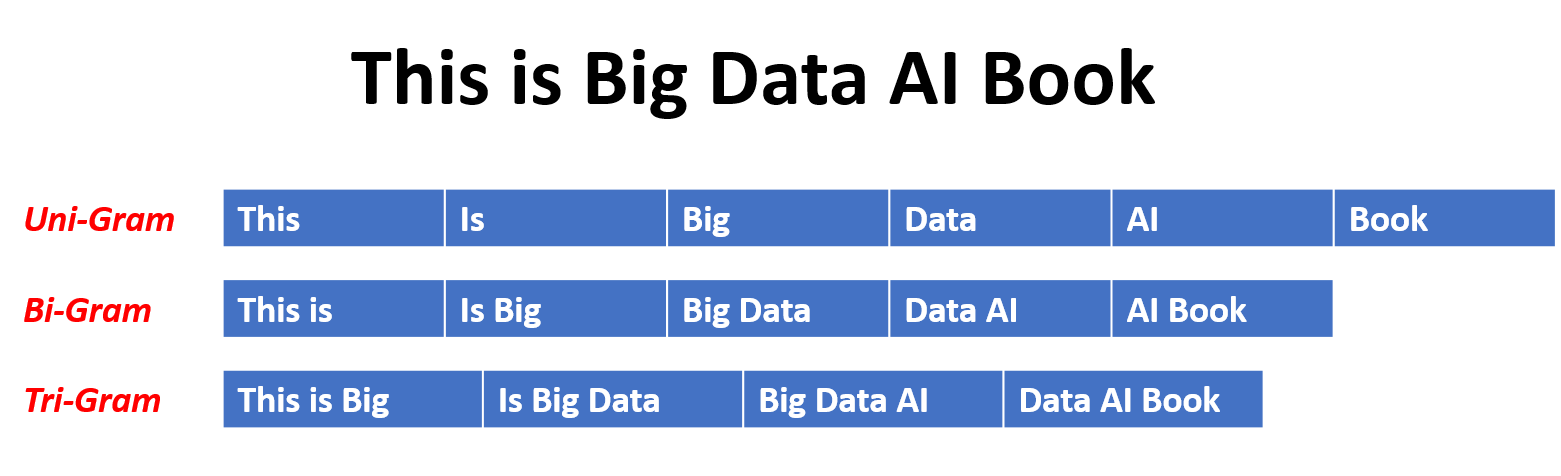
Fig. 1 Visualisierung n-grams, von [Mehmood, 2020].#
N-gram-Modelle sind einfach und schnell zu trainieren und können eine relativ gute Leistung erzielen.
Allerdings sind sie aufgrund ihrer begrenzten Kontextgröße und ihrer Unfähigkeit, semantische Beziehungen zwischen Wörtern zu berücksichtigen, oft nicht in der Lage, hochwertige und natürliche Texte zu generieren.
Google hat über lange Zeiträume und große Textdatenmengen die Häufigkeiten von n-grams erhoben. Diese sind öffentlich zugreifbar und erlauben so direkt einen Vergleich zwischen verschiedenen n-grams, z.B. für verschiedene Programmiersprachen auf https://books.google.com/ngrams/.
Ziel von Task A.1#
n-gram werden als einfaches statistisches Modell vorgestellt und in der ersten Aufgabe implementiert sowie die Statistik aus einem kurzen Textcorpus extrahiert.
Ihre Aufgabe ist es ein C++ Programm zu implementieren, das die Häufigkeiten von n-grams für verschiedene \(n\) bestimmt (mindestens bis zu Ebene \(n=2\) aber auch \(n=\) ist noch empfehlenswer). Dazu sollen sie die benötigten Funktionen in C++ implementieren. Sie müssen hierbei Entscheidungen über den Ablauf und die aufzubauende Repräsentation für die n-grams treffen.
Sie bekommen schon hierfür vorgegebene Routinen zum einlesen von Text und zur Vorverarbeitung von Text .
Grundlegende Struktur#
#include <iostream>
#include "read_file.h"
#include "count_ngram.h"
int main(int argc, const char* argv[])
{
/* Parsing input arguments for main method:
* Required:
* --input Input file in which the n-grams shall be counted
*/
// Provide help on how to call main.
if (argc < 3) {
std::cerr << "Usage: " << argv[0] << " --input InputFile" << std::endl;
return 1;
}
// Setting up the variables.
std::string input_file;
// Parsing the arguments.
for (int i = 1; i < argc; ++i) {
std::string argument = argv[i];
// Parsing for input file.
if (std::string(argv[i]) == "--input") {
if (i + 1 < argc) { // Make sure we aren't at the end of argv!
input_file = argv[++i]; // Increment 'i' so we don't get the argument as the next argv[i].
} else { // There was no argument to the input file option.
std::cerr << "--input option requires one argument." << std::endl;
return 1;
}
}
}
// Read text from file into a vector of strings (remove punctuation).
std::vector<std::string> full_text = readTextFromFile( input_file );
// Produce the counts for the n-grams for n=1 to 3.
auto count_1gram = count1gramFromText( full_text );
// auto count_2gram = countBiGramFromText( full_text );
// auto count_3gram = count3GramFromText( full_text );
// Check for count of specific words and the most counted n-gram.
std::cout << "Most used word = \"" << findMax1gram(count_1gram) <<
"\" - count : " << getCountFor1gram( count_1gram, findMax1gram(count_1gram) ) << std::endl;
}
#include <string>
#include <vector>
//#include <tbd_type>
// You have to decide for the type of the representation - it should store the string and a count for each string.
tbd_type count1gramFromText( const std::vector<std::string> full_text );
// ToDo: What should be the type of this function?
//tbd_type_2 countBiGramFromText( const std::vector<std::string> full_text );
// You also might want to go for trigrams.
// Access functions:
// Return the word with the highest count
std::string findMax1gram (const tbd_type& count_Ngram);
// Get a count for a string.
int getCountFor1gram(const tbd_type& count_Ngram, const std::string& str);
// Implement similar functions for bigrams and trigrams.
CXX := c++
CXXFLAGS := -Wall -Werror -std=c++20
# Contain path for any includes (headers)
INCLUDES := -I./include
# Contains libraries we need to (-L is directory search path, -l is lib)
#LDFLAGS = -L/usr/local/lib -L/opt/homebrew/lib
#LDLIBS = -lcurl -lssl -lcrypto
SRCDIR := ./src
NGRAM_OBS = read_file.o count_ngram.o main_ngram.o
ngramcount: $(NGRAM_OBS)
$(CXX) $^ -o $@ $(LDLIBS)
%.o: $(SRCDIR)/%.cpp
$(CXX) $(INCLUDES) $(CXXFLAGS) -c $^ -o $@
make ngramcount
./ngramcount --input data/sample.txt
Anweisungen
Starten sie im main-Program und verstehen sie einmal die Verarbeitung der Parameter.
Implementieren sie dann als erstes die Function
count1gramFromText(die Vorverarbeitung wird inread_file.cppdurchgeführt, können sie aber überspringen). Hierfür müssen sie eine geeignete Repräsentation und damit einen Datentyp festlegen. Diese Repräsentation ist Rückgabewert der Funktion.Implementieren sie dann Funktionen, die auf diesme Datentyp arbeiten und z.B. den Count für ein n-gram zurückliefern.
Erweitern sie dies nun auf bigrams und gegebenenfalls trigrams (nur wenn genug Zeit, sie sollten noch zumindest eine halbe Stunde für den zweiten Teil haben).
Tipp - hier öffnen
Wählen sie eine geeignete Speicherstruktur als Repräsentation für die n-grams. Überlegen sie auch geeignete Varianten (speziell dann für \(n>1\)). Welche Vor- und Nachteile haben die vers. Strukturen?
Als Hilfe:
Eine Übersicht über Datenstrukturen der STL finden sie in der Referenz oder hier https://en.cppreference.com/w/cpp/container.
Um über diesen zu iterieren siehe in der Referenz zu Iteratoren oder auch https://www.simplilearn.com/tutorials/cpp-tutorial/iterators-in-cpp.
Für die Auswahl von Datenstrukturen bietet https://github.com/gibsjose/cpp-cheat-sheet auch eine gute Übersicht und sogar ein Flowchart.
Beispielergebnisse#
Für den Beispieltext Alice im Wunderland in sample.txt ist das häufigste Wort “the” mit einem count von 1686.
Als zweites Beispiel: Für den Berkeley Restaurant Corpus geben [Jurafsky and Martin, 2009] in der Literatur folgende Werte an: Zuerst eine Tabelle mit counts für Unigrams (für \(8\) Wörter von insgesamt \(V=1446\) über den Berkeley Restaurant Corpus aus \(9332\) Sätzen), Ergebnisse nach [Jurafsky and Martin, 2009].
i |
want |
to |
eat |
chinese |
food |
lunch |
spend |
|---|---|---|---|---|---|---|---|
2533 |
927 |
2417 |
746 |
158 |
1093 |
341 |
27 |
Tabelle mit counts für Bigrams (für \(8\) Wörter von insgesamt \(V=1446\) über den Berkeley Restaurant Corpus aus \(9332\) Sätzen) – Einträge in der vertikalen ersten Spalte geben das vorherige Wort an und die folgenden Spalten geben dann die gezählten Häufigkeiten für die in der oberen Zeile angegebenen Wörter wieder [Jurafsky and Martin, 2009].
i |
want |
to |
eat |
chinese |
food |
lunch |
spend |
|
|---|---|---|---|---|---|---|---|---|
i |
5 |
827 |
0 |
9 |
0 |
0 |
0 |
2 |
want |
2 |
0 |
608 |
1 |
6 |
6 |
5 |
1 |
to |
2 |
0 |
4 |
686 |
2 |
0 |
6 |
211 |
eat |
0 |
0 |
2 |
0 |
16 |
2 |
42 |
0 |
chinese |
1 |
0 |
0 |
0 |
0 |
82 |
1 |
0 |
food |
15 |
0 |
15 |
0 |
1 |
4 |
0 |
0 |
lunch |
2 |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
spend |
1 |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
Der heutige Corpus (in data/berkeley.txt) enthält ein paar Einträge mehr, so dass man zu leicht anderen Ergebnissen kommt, aber im allgemeinen sind die Tendenzen (und Wahrscheinlichkeiten) gleich. Für die Unigrams ergibt sich so zum Beispiel:
i |
want |
to |
eat |
chinese |
food |
lunch |
spend |
|---|---|---|---|---|---|---|---|
3877 |
1043 |
2734 |
833 |
193 |
1247 |
392 |
311 |
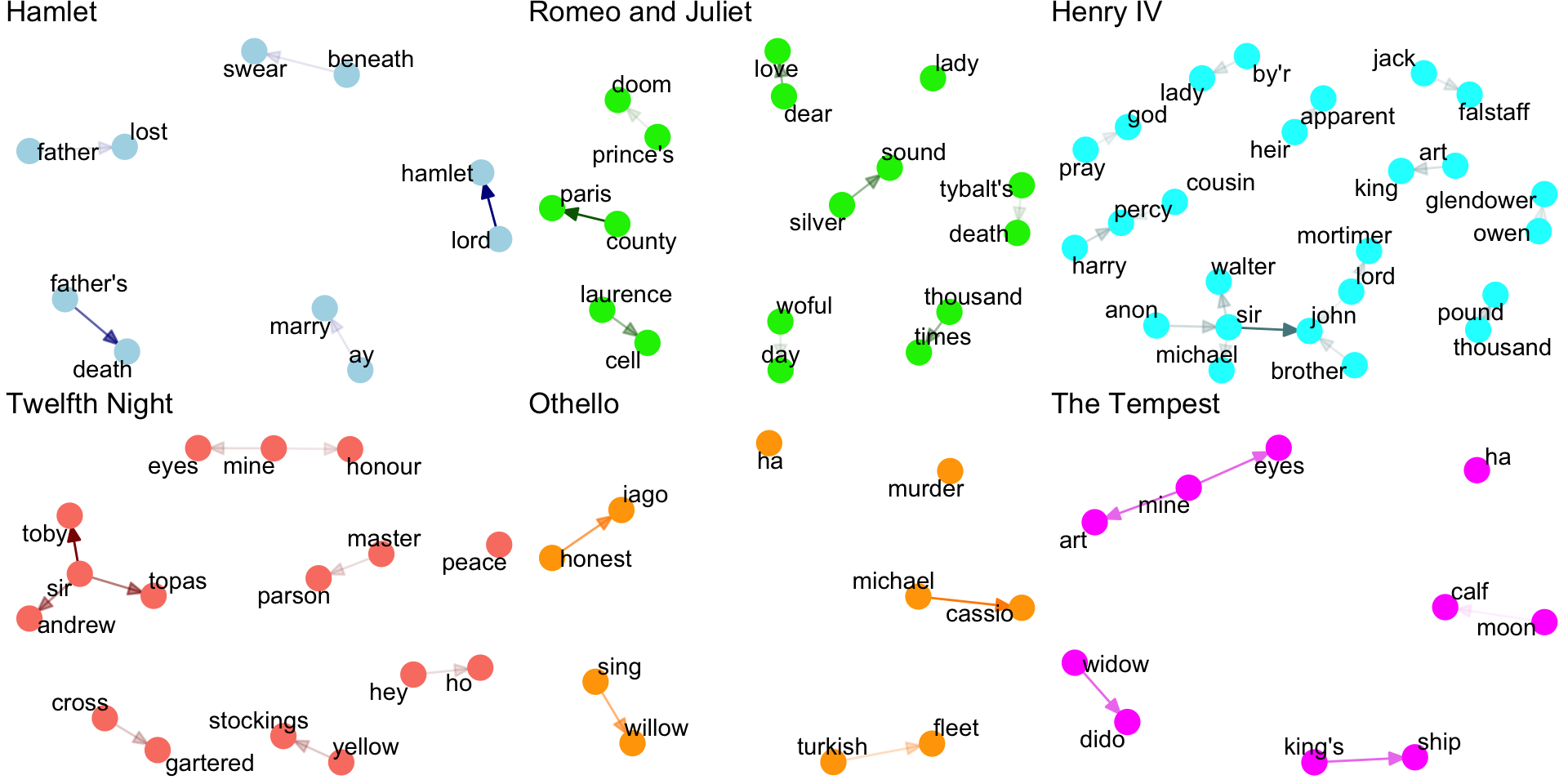
Fig. 2 Beispiel einer Visualisierung von den häufigsten Bigrams in vers. Shakespeare Stücken (nach Entfernung der Regieanweisungen), siehe [Ackermann, 2020].#
Mögliche Erweiterung#
Mögliche Erweiterungen: Speichern sie die gewonnene Statistik.
Referenzen#
Mehr Hinweise für die effiziente Implementierung von Algorithmen und Strukturen für n-grams finden sich in
der Forschung, siehe z.B. [Pibiri and Venturini, 2019];
entsprechenden spezialisierten libraries, wie z.B. tongrams.
- 1
L.M. Ackermann. Processing shakespeare. Blogpost., 2020. URL: https://lmackerman.com/AdventuresInR/docs/shakespeare.nb.html#n-grams.
- 2(1,2,3)
Daniel Jurafsky and James H. Martin. N-grams. In Speech and Language Processing, chapter 4. Prentice-Hall, Englewood Cliffs, NJ, 2009.
- 3
Arshad Mehmood. Generate unigrams-bigrams-trigrams-ngrams etc. in python. Blogpost., 2020. URL: https://arshadmehmood.com/development/generate-unigrams-bigrams-trigrams-ngrams-etc-in-python/.
- 4
Giulio Ermanno Pibiri and Rossano Venturini. Handling massive n-gram datasets efficiently. ACM Trans. Inf. Syst., feb 2019. URL: https://doi.org/10.1145/3302913, doi:10.1145/3302913.