Praktikum zu Vorlesung Modellreduktion parametrisierter Systeme
Mario Ohlberger, Felix Schindler, Tim Keil
Blatt 04, 15.05.2019¶
Aktivieren Sie wie gewohnt ihre Arbeitsumgebung und starten Sie den Jupyter Notebook server, siehe zB Blatt 1, Aufgabe 0.
Erstellen Sie ein neues
Python 3Notebook oder laden Sie dieses von der Homepage herunter.Laden Sie die Bilder RB.png, R.png, B.png von der Homepage herunter.
Importieren Sie
numpyundpymor.basicund machen Siematplotlibfür das Notebook nutzbar.
%matplotlib notebook
import numpy as np
from pymor.basic import *
Aufgabe 1: parametrische Diffusion¶
Wir betrachten wieder das Diffusionsproblem aus Blatt 03, Aufgabe 2. In dieser Aufgabe wollen wir die zugehörige Diffusion $A_\mu$ parametrisieren, d.h. wir suchen zu einem Parameter $\mu \in \mathbb{R}$ eine schwache Lösung $u_\mu \in H^1(\Omega)$, sodass
$$\begin{align} -\nabla\cdot( A_\mu \nabla u_\mu ) &= f &&\text{in } \Omega\\ u_\mu &= g_\text{D} &&\text{auf } \Gamma_\text{D}\\ - (A_\mu \nabla u_\mu) \cdot n &= g_{\text{N}} &&\text{auf } \Gamma_\text{N}\\ \end{align}$$für die Datenfunktionen
- $f = 0$
- $g_\text{D} = 0$
- $g_\text{N} = -1$
- Legen Sie erneut die zugehörigen Datenfunktionen für $f, g_\text{D}, g_\text{N}$ und die zugehörige Domaindiskretiserung an.
domain = RectDomain([[0,0],[1,1]], bottom='neumann')
force = ConstantFunction(0,2)
dirichlet_data = ConstantFunction(0,2)
neumann_data = ConstantFunction(-1,2)
- Nun wollen wir zunächst eine nichtparametrische Diffusion $A_\mu$ betrachten. Die
BitmapFunctionverwendet die Python Imaging Library (PIL) um ein Graustufenbild in üblichen Grafik-Dateiformaten einzulesen. Wir verwenden hier die folgende Grafik: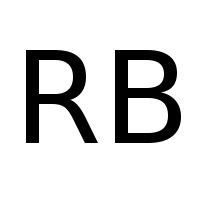 Machen Sie sich mit der Benutzung der
Machen Sie sich mit der Benutzung der BitmapFunctionvertraut und nutzen Sie die Funktion um ihre Diffusion $A_\mu$ zu definieren. Hinweis: Achten Sie darauf, dass dierangeder Funktion nicht bis $0$ gehen darf, da sonst das Problem keine Lösung hätte.
# BitmapFunction?
diffusion = BitmapFunction('RB.png', range=[0.001, 1])
- Legen Sie zu den oben genannten Datenfunktionen ein
StationaryProblemmit dem Namenproblem_3an.
problem_3 = StationaryProblem(
domain=domain,
diffusion=diffusion,
neumann_data=neumann_data
)
- CG-Diskretisieren Sie
problem_3und visualisieren Sie die Lösung. Wählen Sie hierbei die Gitterweite klein genug, damit das RB zu erkennen ist.
set_log_levels({'pymor': 'WARN'})
d, data = discretize_stationary_cg(problem_3, diameter=1/100)
d.visualize(d.solve())

- Benutzen Sie die Diskretiserung und die Lagrange interpolation der vorherigen Zettel um die Diffusion zu visualisieren.
from interpolations import interpolate_lagrange_p1
d.visualize(interpolate_lagrange_p1(problem_3.diffusion, data['grid']))

- Nun wollen wir $A_\mu$ parametrisieren. Dazu trennen wir den RB string in seine einzelnen Buchstaben auf. Wir benötigen also die einzelnen Grafiken für die Buchstaben 'R' und 'B':
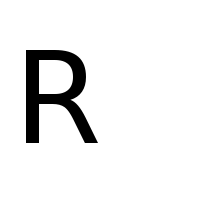
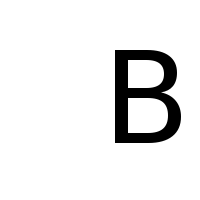 Verwenden Sie erneut die
Verwenden Sie erneut die BitmapFunctionum eine Diffusion auf R und B zu definieren. Erlauben Sie dieses mal, dass dierangeder Bilder auch $0$ sein darf.
diffusion_R = BitmapFunction('R.png', range=[1, 0])
diffusion_B = BitmapFunction('B.png', range=[1, 0])
Um diese Funktionen zu einer Gesamt-Funktion zusammenzusetzen verwenden wir eine
LincombFunctiondie eine Liste von Funkionen und eine Liste von Linearkoeffizieten erhält . Parametrische Linearkoeffizienten werden mit Hilfe vonParameterFunktionalen(siehepymor.parameters.functionals) realisiert. Erstellen Sie eineLincombFunction, die einen Konstanten Hintergrund mit Wert, und beide parametrisierten Buchstaben zu Linearkombination vereint.- Hinweis: Hierbei soll die Wahl $\mu_R = 1$ bzw. $\mu_B = 1$ bedeuten, dass der entsprechende Buchstabe vollständig aus dem Lösungsbild verschwindet.
# LincombFunction?
diffusion = LincombFunction(
[ConstantFunction(1., 2), diffusion_R, diffusion_B],
[1, ExpressionParameterFunctional('-(1 - R)', {'R': ()}), ExpressionParameterFunctional('-(1 - B)', {'B': ()})]
)
print(diffusion.parameter_type)
- Definieren sie ihr parametrisiertes Problem und diskretiseren Sie es erneut mit CG und Gitterweite 1/100.
problem = StationaryProblem(
domain=domain,
diffusion=diffusion,
neumann_data=ConstantFunction(-1, 2)
)
d, data = discretize_stationary_cg(problem, diameter=1/100)
- Lösen und visualisieren Sie das Problem. Wählen Sie ihre Parameter jeweils so, dass beide, nur das R und nur das B in der Lösung zu erkennen sind. Hierbei ist es wichtig, dass die Zuvor definierte
LincombFunctiondies überhaupt ermöglicht.
d.visualize(d.solve([1., 0.001]))
d.visualize(d.solve([0.001, 1]))
d.visualize(d.solve([0.001,0.001]))



Aufgabe 2: Parameterräume¶
Wir wollen nun das oben definierte Problem mit einem Parameterraum ausstatten.
- Benutzen Sie ihre Diskretisierung aus Teilaufgabe 7 um eine neue Diskretisierung anzulegen, die mit einem kubischen Parameterraum ausgestattet ist. Finden Sie die entsprechende Klasse im
pymor.parametersPackage in der Dokumentation.
print(d.parameter_type)
print(d.parameter_space)
d = d.with_(parameter_space=CubicParameterSpace(d.parameter_type, 0.001, 1.))
print(d.parameter_space)
- Mit einem
ParameterSpacekann man eine Menge von Parametern wählen (zum Beispiel um einen Greedy Algorithmus auszuführen). Erstellen Sie zunächst mit Hilfe des zuvor angelegten ParameterSpaces 100 gleichverteilte Parameter und geben Sie diese aus. Überprüfen Sie die Anzahl der so erstellten Parameter.
mus = d.parameter_space.sample_uniformly(10)
print(len(mus)) # obwohl 10 gesampled wurden haben wir 100 parameter, nml 10 bzgl. jeder parameterdimension!
# die zahl gibt also die Anzahl der samplingpunkte pro Dimension an.
for mu in mus:
print(mu)
- Erstellen Sie nun 5 zufällig gewählte Parameter. Wie können Sie diesen Zufall dennoch deterministisch kontrollieren? Erstellen Sie zweimal hintereindern die selbe "zufällige" Menge von Parametern.
for mu in d.parameter_space.sample_randomly(5, seed=1): # hier gibt 10 wirklich die Zahl der Parameter an, die "zufällig" generiert werden
print(mu)
for mu in d.parameter_space.sample_randomly(5):
print(mu) # Hier kommt nicht das selbe wie oben rausraus
for mu in d.parameter_space.sample_randomly(5, seed=1):
print(mu) # Hier schon
- Erstellen sie mit 30 zufälligen Parametern eine Menge von Lösungsvektoren. Speichern Sie die erhaltenen Lösungen in einem
VectorArray U.
U = d.solution_space.empty()
print(type(U))
for mu in d.parameter_space.sample_randomly(30):
U.append(d.solve(mu))
print(len(U))
print(U.dim)
- Visualisieren Sie das
VectorArray U. Warum schlägt dies fehl? Wie können Sie den Fehler lösen?
d.visualize(U)

- Geben Sie außerdem die $H^1$- und die $H^1_0$- Normen der Vektoren in
Uaus.
print('H^1-Norm:', d.h1_0_norm(U)) # norm pro Vektor in U
print('H^1_0-Norm:', d.h1_0_semi_norm(U))
assert np.all(d.h1_0_semi_norm(U) <= d.h1_0_norm(U))
Achtung: d besitzt außerdem die Normen d.h1_norm und d.h1_semi_norm, die sich von obigen nur um die Randwertbehandlung der zugrunde liegenden Systemmatrizen unterscheiden. Bei der Berechnung von Normen von $H^1_0$-Funktionen liefern beide Varianten das selbe Ergebnis. Für die Berechnung von Riesz-Repräsentanten muss jedoch unbedingt das für den jeweiligen Raum ($H^1$ bzw. $H^1_0$) korrekt assemblierte Skalarprodukt verwendet werden.
Aufgabe 3: Approximierbarkeit einer Menge von Vektoren¶
Eine Menge von Vektoren $u_1, \dots, u_{30} \in V$ eines Hilbertraumes $V$ bilden einen Unterraum $U \subset V$, dessen Elemente Linearkombinationen der $u_i$ sind. Betrachten wir zu diesem Unterraum den Operator $\underline{U}: \mathbb{R}^{30} \to V$, der den Vorfaktoren der Linearkombination die fertige Linearkombination zuordnet, dann ist die Matrixdarstellung des Operators $\underline{U} \in \mathbb{R}^{\dim(V) \times 30}$ genau gegeben, indem die $i$te Spalte von $\underline{U}$ der Vektor $u_i$ ist. Damit ist klar, dass die Anwendung des Operators, also die Matrix/Vektor Multiplikation genau die Linearkomintaion ist). Dann gilt, dass der von $u_1, \dots, u_{30}$ aufgespannte Unterraum $U \subset V$ genau mit dem Bild des Operators übereinstimmt.
Ein Ziel der Modellreduktion ist es, einen Unterraum kleinerer Dimension zu finden, der eine hinreichend gute Approximation des zu reduzierenden Unterraumes $U$ ist. Dazu können wir untersuchen wie gut wir das Bild des zugehörigen Operators approximieren können.
Als linearer Operator zwischen endlichdimensionalen Hilberträumen ist der Operator kompakt, d.h. mit dem Spektralsatz aus der Funktionalanalysis ist eine Basis von $U$ genau durch die Links-Singulärvektoren des Operators gegeben. Die "Wichtigkeit" der Elemente der Basis wird durch die Größe des Singulärwertes angezeigt, der zum Vektor gehört.
Schauen wir uns also die Singulärwertzerlegung der Matrixdarstellung von Operatoren an.
- Wir starten mit einem sehr einfachen Beispiel eines nicht approximierbaren Operators.
- Erstellen Sie eine Einheitsmatrix die der Länge von
Uaus Aufgabe 2 entspricht. - Finden Sie eine Möglichkeit die zugehörigen Singulärwerte zu berechnen und geben Sie diese aus.
- Erstellen Sie einen Plot der den Abfall der Singulärvektoren für diesen Fall darstellt. Was fällt Ihnen auf?
- Erstellen Sie eine Einheitsmatrix die der Länge von
from scipy.linalg import svdvals
SVALS = svdvals(np.eye(len(U)))
print(SVALS)
from matplotlib import pyplot as plt
plt.figure()
plt.semilogy(SVALS/np.max(SVALS), label='decay of normalized singular values')
plt.legend()

- Betrachten Sie nun die Vektoren in $U$. Da $U$ aus Lösungen der PDE für zufällige Paramter besteht, wissen wir nicht, ob diese linear abhängig sind und wie gut sie durch eine kleinere Menge von Vektoren approximiert werden können. Berechnen Sie die Singulärwerte und stellen sie den Abfall wieder grafisch dar.
SVALS = svdvals(U.data)
print(SVALS)
plt.figure()
plt.semilogy(SVALS/np.max(SVALS), label='decay of normalized singular values')
plt.legend()

Grob gesagt: um alle Vektoren in U mit einer relativen Genauigkeit von $10^{-3}$ zu approximieren genügen ca. 5 Vektoren (Modellreduktion kann also erfolgreich sein). Es ist aber dennoch nicht klar welche Vektoren diese 5 Vektoren sind.
Wenn man schon alle Vektoren berechnet hat und an der $L^2$ Bestapproximation interessiert ist, dann dies die Linkssingulärvektoren zu den größten Singulärwerten, siehe oben. Dann ist unsere Modellreduktion aber unter Umständen nicht mehr notwendig, da wir schon jede Lösung bestimmt haben.
Man will aber nicht vorher alle Vektoren berechnen, da kommt dann der Greedy Algorithmus ins Spiel.
In jedem Fall benötigt man eine Projektion auf einen Unterraum, der von nur wenigen Vektoren aufgespannt wird (zB von U, oder von einer Teilmenge). Außerdem muss der Approximationsfehler hinreichend klein sein. Dazu später mehr...